近日,多媒体计算领域CCF A类顶级会议ACM MM2025(ACM International Conference on Multimedia)公布了论文的评审结果,杭州电子科技大学计算机学院多个科研团队的研究成果被该会议录用。ACM MM 是中国计算机学会(CCF)推荐的A类国际学术会议,今年为第33届会议,将于2025年10月27日至31日在爱尔兰都柏林举行。
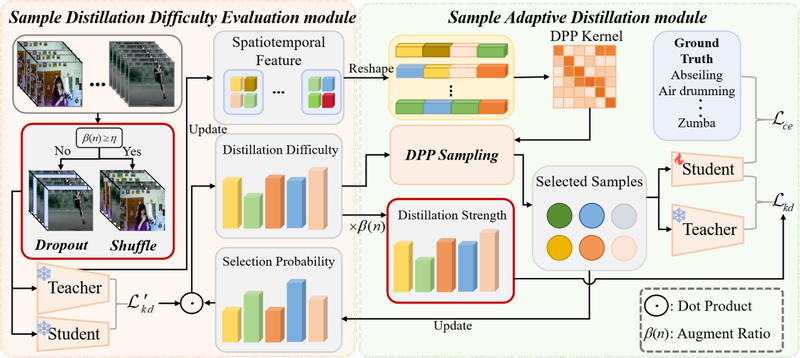
成果一:“Sample-level Adaptive Knowledge Distillation for Action Recognition”,该成果由计算机学院李平教授、23级硕士生平晨昊以及浙大的王闻箫博士、宋明黎教授等人共同合作完成。该成果主要研究以知识蒸馏为核心的视觉模型压缩技术,提出一种样本级自适应知识蒸馏方法用于动作识别任务。具体来说,该方法主要包含时序动态增强模块和自适应蒸馏模块;前者采用了随机丢弃—顺序交换策略,早期训练中随机丢弃一些帧,后期训练中按序交换来自不同动作实例的帧;后者自适应地学习样本级的KD损失和交叉熵损失比值,使得KD损失主导易蒸馏样本的训练,交叉熵损失主导难蒸馏样本的训练;然后选择具有蒸馏分数高和多样性大的少量样本训练学生模型,从而在减少动作模型参数量的同时降低训练开销。该成果对基于深度神经网络的视频模型压缩研究具有重要价值,通过降低计算和存储开销以便于模型部署在资源受限设备上,可用于机器人交互、具身智能、智慧安防等高效且低延迟视频处理的实际场景中。
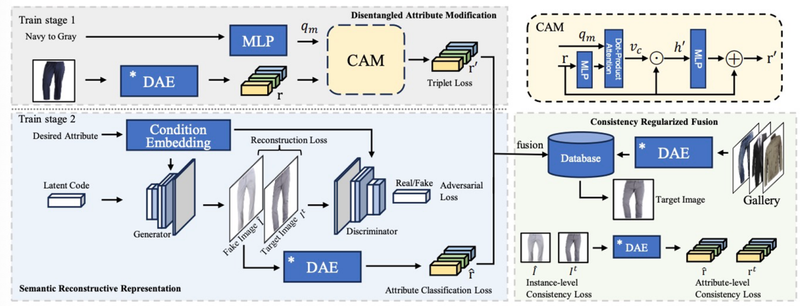
成果二:“DiSCo: Disentangled Attribute Manipulation Retrieval via Semantic Reconstruction and Consistency Regularization”,该成果的第一作者为计算机学院谭敏教授,通讯作者是新加坡A*STAR的研究员詹惠静博士,合作作者还有来自阿里巴巴的冯银付博士,由媒体智能实验室、新加坡A*STAR和阿里巴巴合作完成。该成果针对现有的时尚检索方法往往忽视了时尚图像在分布特性上的独特性,并且在进行属性编辑时难以保持语义一致性的问题,提出了一种通过语义重建与一致性正则化实现解耦属性操作的时尚检索新框架;在两个基准数据(DeepFashion 和 Shopping100K)上的广泛评估表明,DiSCo 在保持高保真属性编辑的同时,在检索准确率方面显著优于现有的先进方法;定量与定性分析进一步证实了本框架在生成更真实的时尚表示方面的有效性,充分体现了其在属性感知检索任务中的潜力。
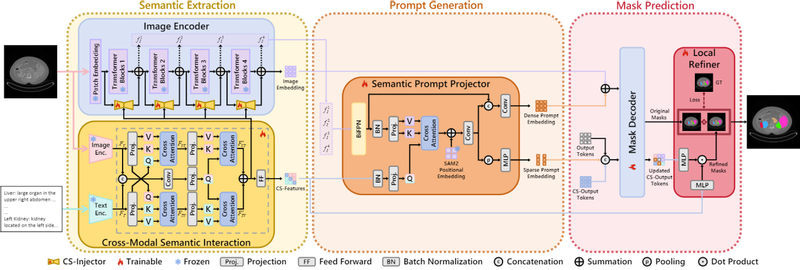
成果三:“CRISP-SAM2 : SAM2 with Cross-Modal Interaction and Semantic Prompting for Multi-Organ Segmentation”,该成果第一作者为计算机学院21级本科生俞鑫磊,通讯作者为计算机学院葛瑞泉副教授和深圳大数据研究院王昌淼副研究员,22级本科生金辉、计算机学院贾刚勇副教授、深圳大学 Ahmed Elazab博士、深圳大数据研究院万翔教授、浙江大学邹常青教授等人共同合作完成。该成果主要研究以跨模态交互和语义提示为核心的医学影像分割技术,提出一种基于 SAM2 的 CRISP-SAM2 模型用于多器官分割任务。具体来说,该方法主要包含渐进式跨模态语义交互模块、语义提示投影器、局部优化器和相似性排序自更新策略。首先通过两级交叉注意力机制融合视觉与文本特征,生成跨模态语义并注入图像编码器以增强视觉细节理解;语义提示投影器利用跨模态语义和多尺度图像特征生成稀疏与密集提示嵌入,替代传统几何提示以消除依赖;局部优化器结合跨模态语义和更新的输出令牌优化分割细节;相似性排序自更新策略通过切片相似度排序和 IoU 过滤更新记忆库,适应 3D 医学影像的空间特性。该方法在七个公开数据集上得到验证,在提升分割精度的同时,减少对几何提示的依赖,降低部署难度。该成果对当前的医学影像分割研究具有重要价值,通过提升分割精度和降低对交互提示的依赖以便于模型部署在临床诊断设备上,可用于疾病诊断、手术规划、影像引导治疗等需要精准器官分割的实际场景中。
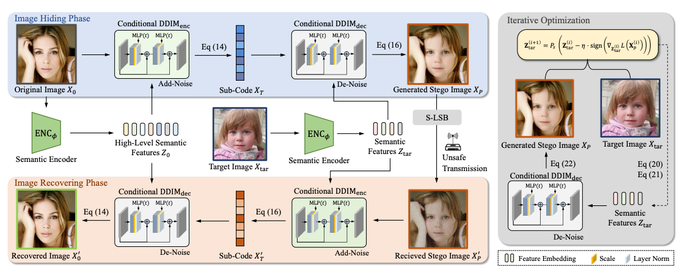
成果四:“F-DDIM: A Featurized Denoising Diffusion Implicit Model for Facial Image Steganography”,该成果由计算机学院颜力琦副教授、23级硕士生李学彬,以及张建辉、管昉立、李攀教授等人共同合作完成;通讯作者为张建辉教授。该成果主要研究以扩散模型为核心的人脸隐私保护加密技术,提出一种新颖的非嵌入式面部图像隐写框架F-DDIM,用于实现更加安全和高质量的隐私保护图像传输。具体来说,该方法针对传统嵌入易导致图像质量下降且容易被检测、以及基于GAN的非嵌入方法缺乏可控性和真实感的问题,通过用图像特征替代可解释的文本提示增强安全性,并通过迭代重建选择性地优化面部区域,从而实现自然且高保真的图像恢复。同时,该方法引入了一种全新的子码嵌入算法,无需共享密钥即可完成不可区分的加密,还在解码后加入细化步骤,进一步提升恢复图像的清晰度与细节准确性。实验结果表明,F-DDIM在图像保真度和抗传输干扰方面均优于现有方法。
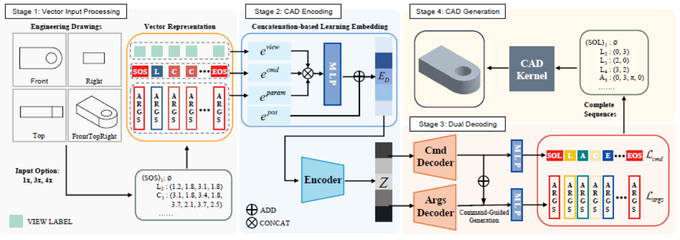
成果五:“Drawing2CAD: Sequence-to-Sequence Learning for CAD Generation from Vector Drawings”,该成果由计算机学院秦飞巍教授、23级硕士生陆世超、浙江大学博士生侯钧皓以及深圳大数据研究院王昌淼副研究员、广州大学方美娥教授、中国科学技术大学刘利刚教授等人共同合作完成。计算机辅助设计(CAD)生成建模正在推动工业应用领域的重大创新。近期的研究在从点云、网格和文本描述等各种输入中创建实体模型方面取得了显著进展。然而,这些方法从根本上偏离了传统工业工作流程——后者通常从二维工程图纸开始。尽管从二维矢量图纸自动生成参数化CAD模型是工程设计中的关键步骤,但这一领域仍鲜有人探索。为了解决这一空白,该成果的主要思路是将CAD生成重新定义为一个序列到序列(Seq2Seq)的学习问题,使矢量图(SVG)的基本绘制图元直接指导参数化CAD操作的生成,在整个转换过程中保持几何精度和设计意图。为此,该成果提出了Drawing2CAD框架,该框架包含三个关键的技术组件:一种网络友好型的向量基元表示,能够保留精确的几何信息;一种双解码器的Transformer架构,能够将命令类型和参数生成解耦,同时保持精确对应;以及一种软目标分布损失函数,能够适应CAD参数的内在灵活性。
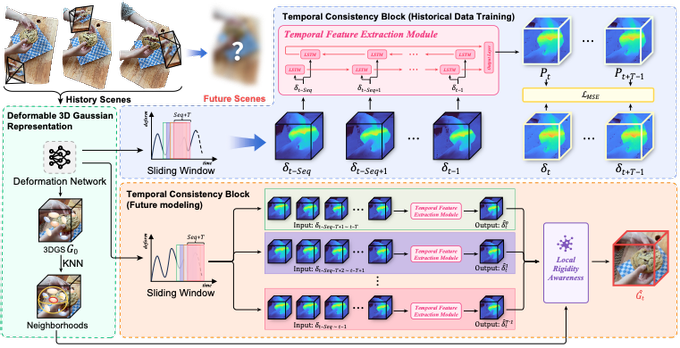
成果六:“FutureGS: Structured Gaussian Fields for Future-Aware Dynamic Scene Modeling”,该成果由计算机学院22级本科生丁铭阳,23级本科生王湛,22级本科生王家晨,23级本科生胡鑫园共同完成,指导老师为媒体智能实验室成员韩婷婷、丁佳骏、谭敏和匡振中等。该成果聚焦于未来动态场景建模这一前沿课题,提出了FutureGS框架,通过结构化的高斯场建模与未来感知的时间建模机制,实现对连续动态场景中未来状态的准确预测与新视角合成。FutureGS引入多窗口协同预测策略与基于Bi-LSTM的时序建模网络,提升了模型对复杂长时序运动的建模能力。同时,FutureGS设计了一种KNN驱动的局部刚性感知融合机制,有效增强了未来视角合成中的几何稳定性与物理可行性。大量实验证明本文提出的方法在未来预测场景的时空一致性与视觉质量均超越现有的方法。